[Clean Architecture] 14장. 컴포넌트 결합
|
Introduction
- 컴포넌트 사이의 관계를 설명
- 개발 가능성과 논리적 설계 사이의 균형을 다룸
- 컴포넌트 구조와 관련된 아키텍처를 침범하는 힘은 기술적이며, 정치적이고, 가변적임
ADP: 의존성 비순환 원칙
컴포넌트 의존성 그래프에 순환 cycle 이 있어서는 안된다.
- 숙취 증후군
- the morning after syndrome
- 많은 개발자가 동일한 소스 파일을 수정하는 환경에서 발생
- 지난 수십 년 동안 이 문제의 해결책으로 두 가지 방법이 발전
- 모두 통신 업계에서 만들어짐
- 주 단위 빌드, weekly build
- 의존성 비순환 원칙, Acyclic Denpendencies Principle, ADP
주 단위 빌드, weekly build
- 중간 규모의 프로젝트에서는 흔하게 사용됨
- 모든 개발자는 일주일의 첫 4일 동안은 신경 안씀
- 5일 중 4일 동안 개발자를 고립된 세계에서 살 수 있게 보장해줌
- 왜 개발자들은 고립된 상태를 좋아할까?
- 5일 중 4일 동안 개발자를 고립된 세계에서 살 수 있게 보장해줌
- 금요일에 프로젝트 통합이 이뤄짐
- 통합이 점점 커지면, 목요일로 옮기게 되고, 점점 한 주의 중반으로 향하게 됨
- 이러면 빌드를 격주로 가겠지만… 다시 반복될 뿐
- 통합과 테스트를 수행하기가 점점 더 어려워지고, 팀은 빠른 피드백이 주는 장점을 잃는다.
순환 의존성 제거하기
- 개발 환경을 릴리스 가능한 컴포넌트 단위로 분리하는 것
- 컴포넌트는 개별 개발자 또는 단일 개발팀이 책임질 수 있는 작업 단위가 됨
- 개발자가 해당 컴포넌트가 동작하도록 만든 후, 해당 컴포넌트를 릴리스하여 다른 개발자가 사용할 수 있도록 만듦
- 릴리스 번호를 부여하고, 릴리스 문서를 사용하고, 필요한 경우 적용하고, 아니면 과거 버전을 그대로 사용하고…
- 어떤 팀도 다른 팀에 의해 좌우되지 않음
- 특정 컴포넌트가 변경되더라도 다른 팀에 즉각 영향을 주지는 않음
- 통합은 작고 점진적으로 이뤄짐
- 이 같은 작업 절차는 단순하며 합리적이어서 널리 사용되는 방식
- 하지만 이 절차가 성공적으로 동작하려면, 컴포넌트 사이의 의존성 구조를 반드시 관리해야 함
- 의존성 구조에 순환이 있어서는 안된다.
- DAG, Directed Acyclic Graph
순환이 컴포넌트 의존성 그래프에 미치는 영향
- 순환이 생기면 서로가 서로에게 얽매이게 되고, 올바른 빌드 순서가 사라짐
순환 끊기
- 컴포넌트 사이의 순환을 끊고 의존성을 다시 DAG 로 원상복구하는 일은 언제라도 가능함
- 이를 위한 주요 매커니즘 두 가지
- 의존성 역전 원칙 (DRP) 를 적용
- 모두가 의존하는 새로운 컴포넌트를 만듦
흐트러짐 (Jitters)
- 두 번째 해결책에서 시사하는 바는 요구사항이 변경되면 컴포넌트 구조도 변경될 수 있다는 사실
- 실제로 애플리케이션이 성장함에 따라 컴포넌트 의존성 구조는 서서히 흐트러지며 또 성장함
- 의존성 구조에 순환이 발생하는지를 항상 관찰해야 함
- 순환이 발생하면 어떤 식으로든 끊어야 함
- 이 말은 때론 새로운 컴포넌트를 생성하거나 의존성 구조가 더 커질 수 있음을 의미
하향식(top-down) 설계
- 지금까지 논의로 우리는 피할 수 없는 결론에 다다르게 됨
- 즉, 컴포넌트 구조는 하향식으로 설계될 수 없음
- 컴포넌트는 시스템에서 가장 먼저 설계할 수 있는 대상이 아님
- 오히려 시스템이 성장하고 변경될 때 함께 진화함
- 이 결론이 직관에 어긋난다고 생각할 수 있음
- 어쨌든 우리는 컴포넌트와 같이 큰 단위로 분해된 구조는 고수준의 기능적인 구조로 다시 분해할 수 있다고 기대하기 때문
- 컴포넌트 의존성 다이어그램은 애플리케이션의 기능을 기술하는 일과는 거의 관련이 없음
- 오히려 컴포넌트 의존성 다이어그램은 애플리케이션의 빌드 가능성 (buildability) 과 유지보수성 (maintainability) 을 보여주는 지도와 같음
- 바로 이러한 이유 때문에 컴포넌트 구조는 프로젝트 초기에 설계할 수 없음
- 빌드하거나 유지보수할 소프트웨어가 없다면 빌드와 유지보수에 관한 지도 또한 필요 없기 때문
- 의존성 구조와 관련된 최우선 관심사는 변동성을 격리하는 것
- 컴포넌트 의존성 그래프는 자주 변경되는 컴포넌트로부터 안정적이며 가치가 높은 컴포넌트를 보호하려는 아키텍트가 만들고 가다듬게 됨
- 애플리케이션이 계속 성장함에 따라 우리는 재사용 가능한 요소를 만드는 일에 관심을 기울이기 시작함
- 이 시점이 되면 컴포넌트를 조합하는 과정에 공통 재사용 원칙 CRP 이 영향을 미치기 시작함
- 아직 아무런 클래스도 설계하지 않은 상태에서 컴포넌트 의존성 구조를 설계하려고 시도한다면 상당히 큰 실패를 맛볼 수 있음
- 공통 폐쇄에 대해 그다지 많이 파악하지 못하고 있고,
- 재사용 가능한 요소도 알지 못하며,
- 컴포넌트를 생성할 때 거의 확실히 순환 의존성이 발생할 것
- 따라서 컴포넌트 의존성 구조는 시스템의 논리적 설계에 발맞춰 성장하며 또 진화해야 함
SDP: 안정된 의존성 원칙
안정성의 방향으로 (더 안정된 쪽에) 의존하라.
- 설계는 결코 정적일 수 없다.
- 변경은 불가피
- 컴포넌트 중 일부는 변동성을 지니도록 설계됨
- 우리는 변동성을 지니도록 설계한 컴포넌트는 언젠가 변경되리라고 예상함
- 변경이 쉽지 않은 컴포넌트가 변동이 예상되는 컴포넌트에 의존하게 만들어서는 절대로 안 된다.
- 한번 의존하게 되면 변동성이 큰 컴포넌트도 결국 변경이 어려워짐
- 안전된 의존성 원칙 SDP 을 준수하면 변경하기 어려운 모듈이 변경하기 쉽게 만들어진 모듈에 의존하지 않도록 만들 수 있음
안정성
- stability
- 안정성은 변경을 만들기 위해 필요한 작업량과 관련
- 소프트웨어 컴포넌트를 변경하기 어렵게 만드는 확실한 방법 하나는 수많은 다른 컴포넌트가 해당 컴포넌트에 의존하게 만드는 것
- 컴포넌트 안쪽으로 들어오는 의존성이 많아지면 상당히 안정적이라고 볼 수 있음
- 사소한 변경이라도 의존하는 모든 컴포넌트를 만족시키면서 변경하려면 상당히 노력이 들기 때문
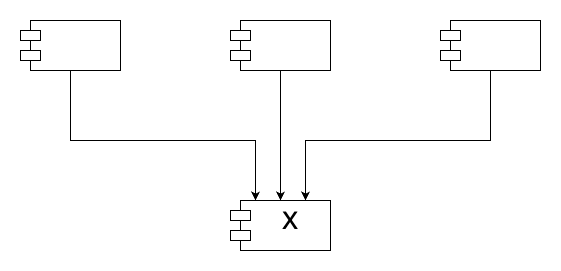
- X 는 안정된 컴포넌트
- 세 컴포넌트가 X 에 의존
- 이 경우 X 는 세 컴포넌트를 책임진다 responsible 라고 말함
- 반대로 X 는 어디에도 의존하지 않으므로 X 가 변경되도록 만들 수 있는 외적인 영향이 전혀 없음
- 이 경우 X 는 독립적이다 independent 라고 말함
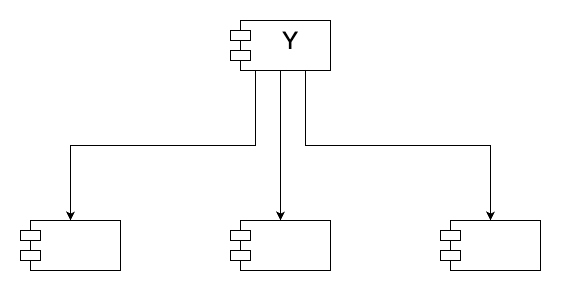
- Y 는 상당히 불안정한 컴포넌트
- 어떤 컴포넌트도 Y 에 의존하지 않으므로 책임성이 없음
- 그리고 Y 는 세 개의 컴포넌트에 의존하므로 변경이 발생할 수 있는 외부 요인이 세 가지
- 따라서 Y 는 의존적
안정성 지표
- 어떻게 하면 컴포넌트 의존성을 측정할 수 있을까?
- 컴포넌트로 들어오고 나가는 의존성의 개수를 세어보는 방법
- Fan-in
- 안으로 들어오는 의존성
- 컴포넌트 내부의 클래스에 의존하는 컴포넌트 외부의 클래스 개수
- Fan-out
- 바깥으로 나가는 의존성
- 컴포넌트 외부의 클래스에 의존하는 컴포넌트 내부의 클래스 개수
I(불안정성)- $I=Fan-out\div(Fan-in+Fan-out)$
- [0, 1] 범위의 값
I= 0- 최고로 안정된 컴포넌트
- 해당 컴포넌트에 의존하는 다른 컴포넌트가 있지만 (Fan-in > 0)
- 해당 컴포넌트 자체는 다른 컴포넌트에 의존하지 않는다 (Fan-out = 0)
- 이러한 컴포넌트는 다른 컴포넌트를 책임지며, 또 독립적
- 최고로 안정된 상태
- 해당 컴포넌트는 변경하기가 어렵지만, 해당 컴포넌트를 변경하도록 강제하는 의존성은 갖지 않음
I= 1- 최고로 불안정한 컴포넌트
- 어떤 컴포넌트도 해당 컴포넌트에 의존하지 않지만, (Fan-in = 0)
- 해당 컴포넌트는 다른 컴포넌트에 의존함 (Fan-out > 0)
- 컴포넌트가 가질 수 있는 최고로 불안정한 상태
- 책임성이 없으며, 의존적
- Fan-in
- SDP 에서 컴포넌트의
I지표는 그 컴포넌트가 의존하는 다른 컴포넌트들의I보다 커야 한다고 말함 - 즉, 의존성 방향은 갈수록
I지표 값이 감소해야 한다.
모든 컴포넌트가 안정적이어야 하는 것은 아니다
- 모든 컴포넌트가 최고로 안정적인 시스템이라면 변경이 불가능함
- 이는 바람직한 상황이 아님
- 사실 우리가 컴포넌트 구조를 설계할 때 기대하는 것은 불안정한 컴포넌트도 있고 안정된 컴포넌트도 존재하는 상태
추상 컴포넌트
- 오로지 인터페이스만을 포함하는 컴포넌트
- 정적 타입 언어를 사용할 때 이 방식은 상당히 흔할 뿐만 아니라, 꼭 필요한 전략
- 이러한 추상 컴포넌트는 상당히 안정적이며, 따라서 덜 안정적인 컴포넌트가 의존할 수 있는 이상적인 대상
SAP: 안정된 추상화 원칙
컴포넌트는 안정된 정도만큼만 추상화되어야 한다.
고수준 정책을 어디에 위치시켜야 하는가?
- 시스템에는 자주 변경해서는 절대로 안되는 소프트웨어도 있다.
- 고수준 아키텍처나 정책 결정과 관련된 소프트웨어가 그 예
- 시스템에서 고수준 정책을 캡슐화하는 소프트웨어는 반드시 안정된 컴포넌트 (
I= 0)에 위치해야 함 - 불안정한 컴포넌트 (
I= 1)는 반드시 변동성이 큰 소프트웨어, 즉 쉽고 빠르게 변경할 수 있는 소프트웨어만을 포함해야 함 - 하지만 고수준 정책을 안정된 컴포넌트에 위치시키면?
- 그 정책을 포함하는 소스 코드는 수정하기가 어려워짐
- 이로 인해 시스템 전체 아키텍처가 유연성을 잃음
- 컴포넌트가 최고로 안정된 상태이면서도 (
I= 0), 동시에 변경에 충분히 대응할 수 있을 정도로 유연하게 만들 수 있을까?- 해답은 개방 폐쇄 원칙, OCP
- 어떤 클래스가 이 원칙을 준수하는가?
- 바로 추상 클래스, abstract class
안정된 추상화 원칙
- Stable Abstractions Principle, SAP
- 안정성 (stabilitity) 과 추상화 정도 (abstractness) 사이의 관계를 정의
- 이 원칙은 한편으로 안정된 컴포넌트는 추상 컴포넌트여야 하며, 이를 통해 안정성이 컴포넌트를 확장하는 일을 방해해서는 안 된다고 말한다.
- 다른 한편으로는 불안정한 컴포넌트는 반드시 구체 컴포넌트여야 한다고 말함
- 컴포넌트가 불안정하므로 컴포넌트 내부의 구체적인 코드를 쉽게 변경할 수 있어야 하기 때문
- 따라서 안정적인 컴포넌트라면 반드시 인터페이스와 추상 클래스로 구성되어 쉽게 확장할 수 있어야 함
- 안정된 컴포넌트가 확장이 가능해지면 유연성을 얻게 되고, 아키텍처를 과도하게 제약하지 않게 됨
- SDP 에서, 의존성이 반드시 안정성의 방향으로 향해야 한다고 말하고
- SAP 에서, 안정성이 결국 추상화를 의미한다고 말하기 때문
- 따라서 의존성은 추상화의 방향으로 향하게 된다.
- 하지만 DIP 는 클래스에 대한 원칙이며, 클래스의 경우 중간은 존재하지 않음
- 클래스는 추상적이거나 아니거나, 둘 중 하나다.
- SDP와 SAP의 조합은 컴포넌트에 대한 원칙이며, 컴포넌트는 어떤 부분은 추상적이면서 다른 부분은 안정적일 수 있다.
추상화 정도 측정하기
- A 지표는 컴포넌트의 추상화 정도를 측정한 값
- 컴포넌트의 클래스 총 수 대비 인터페이스와 추상 클래스의 개수를 단순히 계산한 값
- Nc: 컴포넌트의 클래스 개수
- Na: 컴포넌트의 추상 클래스와 인터페이스의 개수
- A: 추상화 정도, $A=Na\div Nc$
- A 의 값은 [0, 1] 에 존재
- A = 0 → 컴포넌트에는 추상 클래스가 하나도 없다는 뜻
- A = 1 → 컴포넌트는 오로지 추상 클래스만을 포함한다는 뜻
주계열
- 안정성과 추상화 정도 사이의 관계를 정의할 때
- Y축에는 추상화 정도 (A)를, X축에는 안정성 (I) 로 하는 그래프를 그려보자.
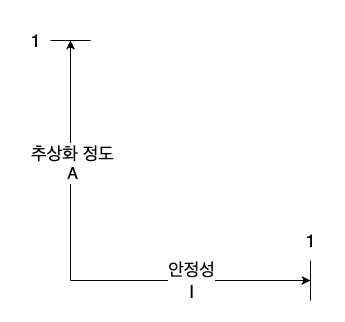
- 최고로 안정적이며 추상화된 컴포넌트는 (0, 1)
- 최고로 불안정하며 구체화된 컴포넌트는 (1, 0)
- 모든 컴포넌트가 이 두 지점에 위치하는 것은 아님
- 따라서 그래프 상에서 컴포넌트가 위치할 수 있는 합리적인 지점을 정의하는 점의 궤적이 있으리라고 가정해보자.
- 우선 배제할 구역을 찾는 방식으로 추론해보자
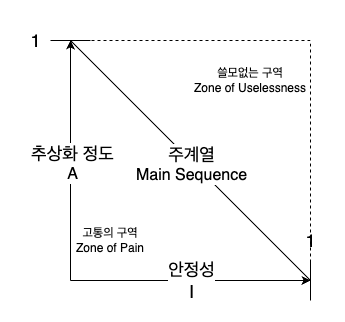
고통의 구역
- 매우 안정적이며 구체적
- 바람직한 상태는 아님, 왜냐하면 뻣뻣하기 때문
- 추상적이지 않으므로 확장할 수 없고,
- 안정적이므로 변경하기도 상당히 어렵다
- 일부 소프트웨어 엔티티가 위치하곤 함
- 데이터베이스의 스키마
- 유틸리티 라이브러리
- 문제가 되는 경우는 변동성이 있는 소프트웨어 컴포넌트이고, 변동성이 클수록 수반되는 고통은 더욱 ‘고통’스러움
쓸모없는 구역
- 최고로 추상적이지만, 누구도 그 컴포넌트에 의존하지 않음
- 이러한 컴포넌트는 쓸모가 없음
- 여기에 존재하는 소프트웨어 엔티티는 폐기물과도 같음
- 아마 누구도 구현하지 않은 채 남겨진 추상 클래스인 경우가 많음
- 쓸모없는 엔티티가 존재한다는 사실은 바람직한 상황이 아님은 분명함
배제 구역 벗어나기
- 이제 각 배제 구역을 벗어나면, 점의 궤적은 (1, 0), (0, 1) 을 잇는 선분인데, 이 선분을 주계열이라고 부르자.
- 주계열에 위치한 컴포넌트는 자신의 안정성에 비해 ‘너무 추상적’이지도 않고, 추상화 정도에 비해 ‘너무 불안정’ 하지도 않음
- 컴포넌트가 추상화된 수준에 어울릴 정도로만 다른 컴포넌트가 의존하며, 구체화된 수준에 어울릴 정도만 다른 컴포넌트에 의존함
- 컴포넌트가 위치할 수 있는 가장 바람직한 지점은 주계열의 두 종점
- 뛰어난 아키텍트라면 대다수의 컴포넌트가 두 종점에 위치하도록 만들기 위해 매진함
- 하지만 저자의 경험상 주계열에 가깝게 위치할 때 이상적
주계열과의 거리
- 세 번째 지표가 도출
- 주계열과의 메트릭
- D
- 거리, distance
- $D=|A+I-1|$
- D의 값은 [0, 1] 에 위치
- D = 0 → 주계열 바로 위에 위치
- D = 1 → 주계열로부터 가장 멀리 위치한다는 뜻
- 각 컴포넌트에 대해 이 지표를 계산하고, 재검토한 후 재구성할 수 있다.
- 설계를 통계적으로 분석하는 일 또한 가능
- 시계열로도 분석 가능!
결론
- 의존성 관리 지표는 설계의 의존성과 추상화 정도가 내가 ‘훌륭한’ 패턴이라고 생각하는 수준에 얼마나 잘 부합하는지를 측정함
- 하지만 지표는 신이 아니다.
- 지표는 단순히 매트릭일 뿐
- 이러한 지표는 아무리 해도 불완전함
- 이들 지표로부터 무언가 유용한 것을 찾을 수 있기를 바람