[그림과 실습으로 배우는 쿠버네티스 입문] 11장. 옵저버빌리티와 모니터링 다루기
|
11.1 관측 가능성에 대해 알아보자
- 시스템이 ‘관측 가능한’ 상태가 되려면 어떻게 해야 할까?
- CNCF 의 백서를 참고해보자.
- 백서에 따르면, 시스템의 출력을 시그널 (signals) 이라고 하며, 선호하는 시그널을 하나 선택하는 것으로 시작하는 것이 좋음
- 또한 시그널에는 주요 시그널 3개와 신규 시그널 2개가 있으며, 주요 시그널부터 시작하는 것이 좋음
- 주요 및 신규 시그널은 다음과 같음
- 주요 시그널 3개
- 로그 (Logs)
- 메트릭스 (Metrics)
- 트레이스 (Traces)
- 신규 시그널 2개
- 프로파일 (Profiles)
- 덤프 (Dumps)
- 이 장에서는 주요 시그널 3개의 의미와 이를 도입하기 위한 대표적인 오픈 소스 소프트웨어 (OSS) 를 소개함
- LGTM? Loki, Grafana, Tempo, Mimir
11.1.1 정보 수집하기: 로그
- 로그를 통해 ‘언제, 무엇이 일어났는지’를 조사할 수 있음
- 쿠버네티스에는 기본으로 설정된 로그 수집 매커니즘이 있어 컨테이너의 표준 출력/오류 (stdout/stderr) 를 컨테이너의 로그로 수집함
- 지금까지 사용한
k logs가 이러한 로그 수집 메커니즘을 사용하고 있음 - 그러나 기본으로 수집되는 로그는 Pod 가 노드에서 삭제되면 사라짐
- 따라서 실제 운영환경에서는 외부로 전송해서 저장해야 함
- 클라우드 서비스에서 제공하는 로그 저장 및 검색 서비스를 사용할 수 있고, OSS 로는 Fluentd, Fluentbit 등이 있음
- 로그를 수집하고 검색할 수 있게 하는 OSS 로는 Grafana Loki 가 있음
- 링크
11.1.2 측정값 처리하기: 메트릭스 (Metrics)
- 측정값의 집합
- 측정값에 대한 통계를 처리하거나 경향을 파악하고자 할 때 사용함
- 로그를 통해서도 많은 정보를 얻을 수 있지만, 그만큼 많은 데이터 용량이 필요함
- 이 때 필요한 것이 메트릭스
- 클라우드 서비스, 외부 클라우드 서비스 (Datadog) 를 이용하는 경우도 많음
- 쿠버네티스는 기본적으로 메트릭스를 수집하는 기능이 없음
- 따라서 메트릭스를 수집하기 위해서는 외부 서비스를 이용해야 함
- 자주 사용되는 OSS: Prometheus
- https://prometheus.io/
11.1.3 통신 추적하기: 트레이스
(시간 ->)
│<------------------ 서비스 A가 처리 완료까지 걸린 시간 ------------------>│
│==================================================================│
│ Trace │
│==================================================================│
+-------------+
| Span | <- 서비스 B 호출
+-------------+
+----------------------+
| Span | <- 데이터베이스 쓰기 작업
+----------------------+
- 트레이스(분산 트레이싱)은 사용자 혹은 애플리케이션의 통신을 추적하기 위한 개념
- 트레이스는 여러 개의 스팬(Span, 작업의 집합)으로 구성됨
- 여러 컨테이너가 실행되는 상황에서 장애가 발생했을 때, 사용자의 요청이 어떤 컨테이너를 거쳤는지 정확히 추적해야 할 때 유용함
- 또한 트레이스를 도입하면 ‘어떤 요청에 얼마나 시간이 걸렸는지’를 세밀하게 시각화할 수 있어 성능 개선 및 튜닝에도 활용할 수 있음
- 특정 컴포넌트나 인프라에만 트레이싱을 도입해서는 의미가 없음
- 정확한 추적을 위해서는 요청이 통과하는 경로의 모든 곳에 트레이스/스팬이 도입되어야 함
- 따라서 로그나 메트릭스에 비해 도입 난도가 높음
- 또한 트레이스를 도입하기 위해서는 애플리케이션의 구현에 손을 대야 함
- 어디서부터 어디까지의 요청을 트레이스로 처리하고, 스팬으로 처리할지를 고려한 후 트레이스/스팬을 표현하는 구현을 추가해야 함
- 구현을 간소화하기 위한 OSS 라이브러리가 있음
- OpenTelemetry 는 트레이스 외에도 메트릭스나 로그 등의 데이터 표준 사양을 정하거나 도구를 제공하는 CNCF 프로젝트임
- 대표적인 OSS 로는 Jaeger, Grafana Tempo 가 있음
11.2 모니터링에 대해 알아보기
11.2.1 정보를 시각화하기: 대시보드
- 관측을 위해서는 시각화가 필요함
- 대시보드를 도입하기 위한 대표적인 OSS 로는 Grafana 가 있음
- LGTM, Loki, Grafana, Tempo, Mimir + Prometheus 을 보통 같이 씀
11.2.2 이상 경보: 알림
- 관측 가능한 상태가 되면 이상이 발생했을 때 빠르게 대응할 수 있도록 알림 설정을 해야 함
- 메트릭스를 기반으로 알림을 설정함
- 대표적인 OSS 로는 Prometheus 의 AlertManager 라는 알림용 컴포넌트를 사용함
11.3 [만들기] 모니터링 시스템 구축하기
- Prometheus + Grafana 를 사용하여 모니터링 시스템을 구축
11.3.1 Prometheus/Grafana 설치하기
| |
11.3.2 메트릭스 수집 애플리케이션 실행하기
- 메트릭스용 엔드포인트를 추가해야 함
- Prometheus 는 /metrics 라는 엔드포인트에 접근하여 메트릭스를 수집함
- /metrics 에서 어떤 메트릭스를 수집할지는 애플리케이션 개발자의 자유
- 구현은 다음과 같이 라이브러리를 추가하고 /metrics 엔드포인트를 추가하면 됨
- 이 애플리케이션을 실행하기 위한 매니페스트가 chapter-11/hello-server.yaml 임
- Prometheus 에서 메트릭스를 수집할 수 있도록 Service 리소스도 추가함
- 또한 Namespace 리소스를 생성하기 위해 chapter-11/namespace.yaml 도 사용
| |
11.3.3 메트릭스 수집을 위한 설정
- Prometheus 는 Pull 방식의 아키텍처
- ‘무엇을 수집할지’ 설정해야 함
- Datadog 는 Push 방식이라 워커노드의 에이전트가 메트릭을 보냄
- 다음 매니페스트를 사용하여 수집을 설정함
- targets 에 수집 대상을 기재함
- 설정 파일을 사용하여
helm upgrade를 진행함
| |
11.3.4 Prometheus에 접속하기
port-forward를 설정하고 접속해보자.
- Status > Target health 를 클릭
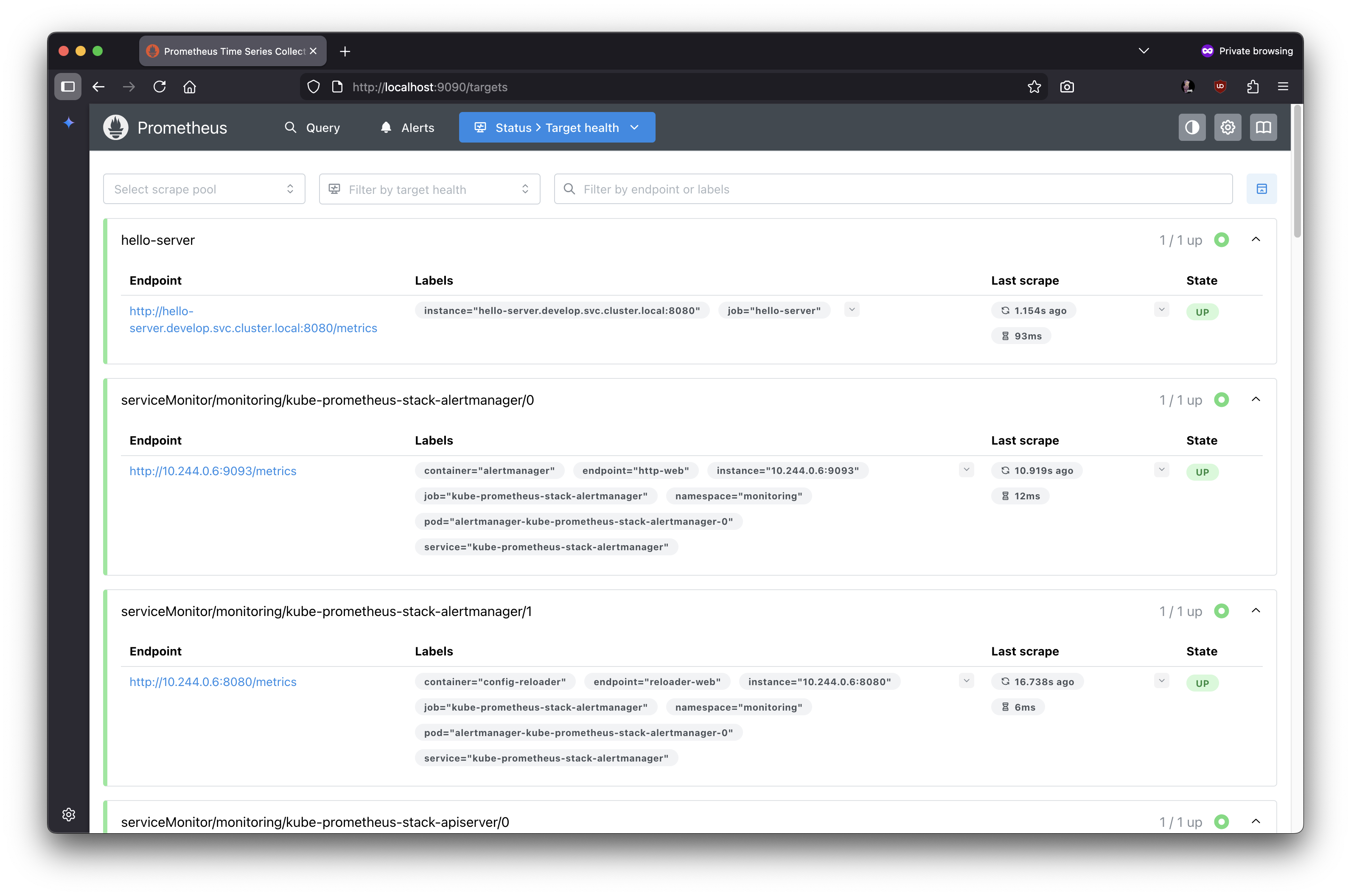
- hello-world 항목을 확인
- UP 이면 인식이 잘 된 것
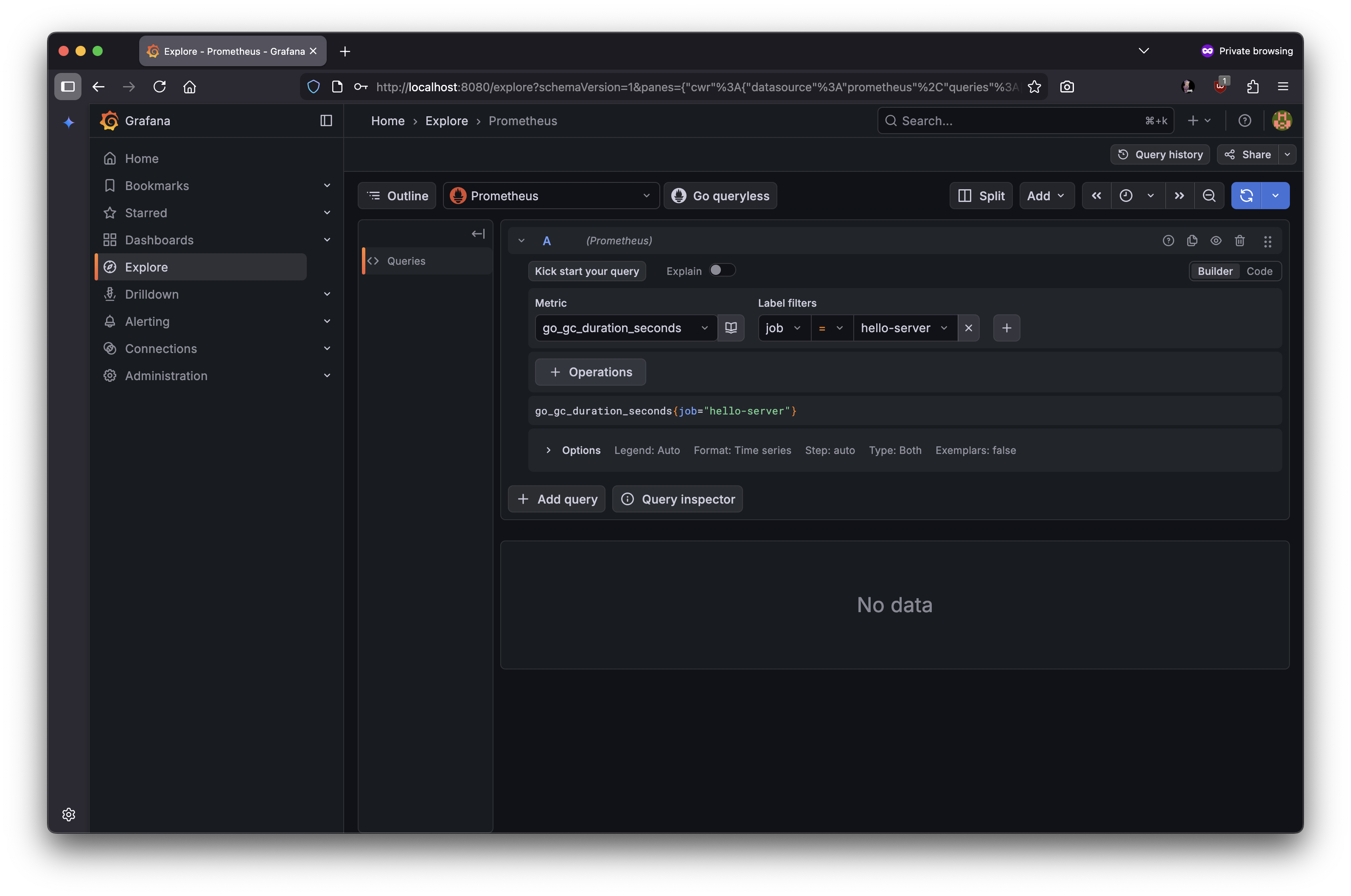
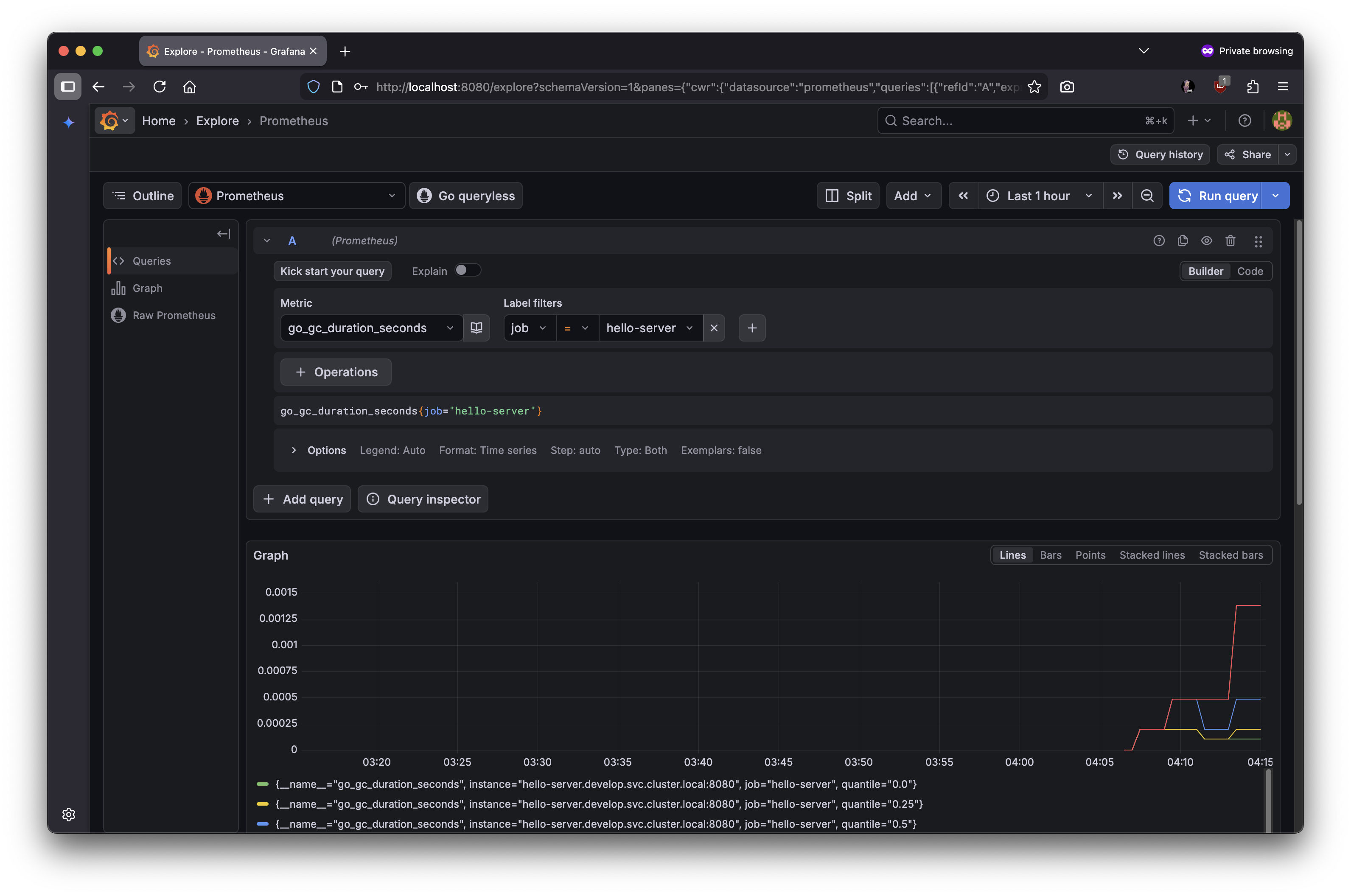
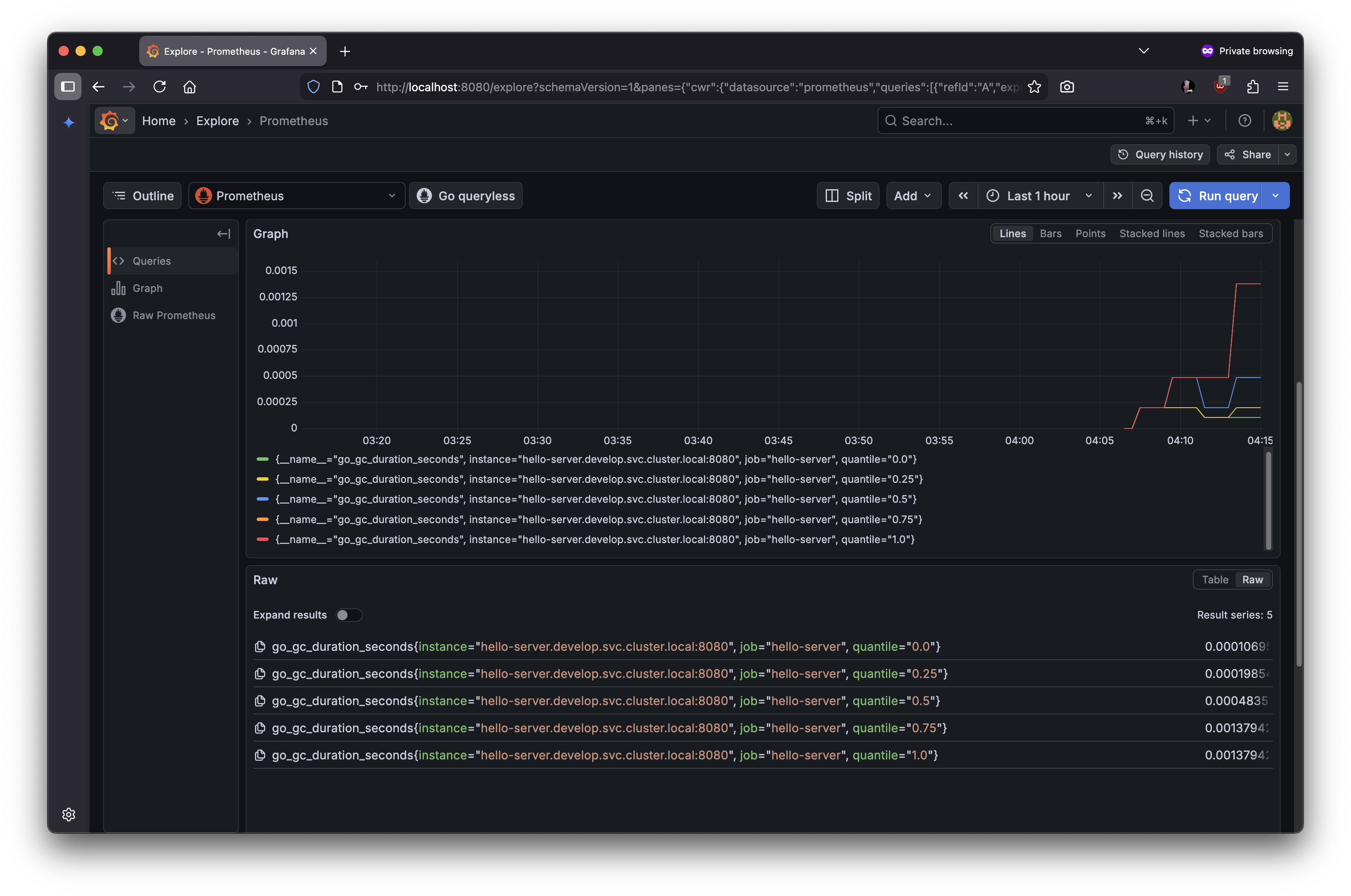
- 실제 메트릭스 조회
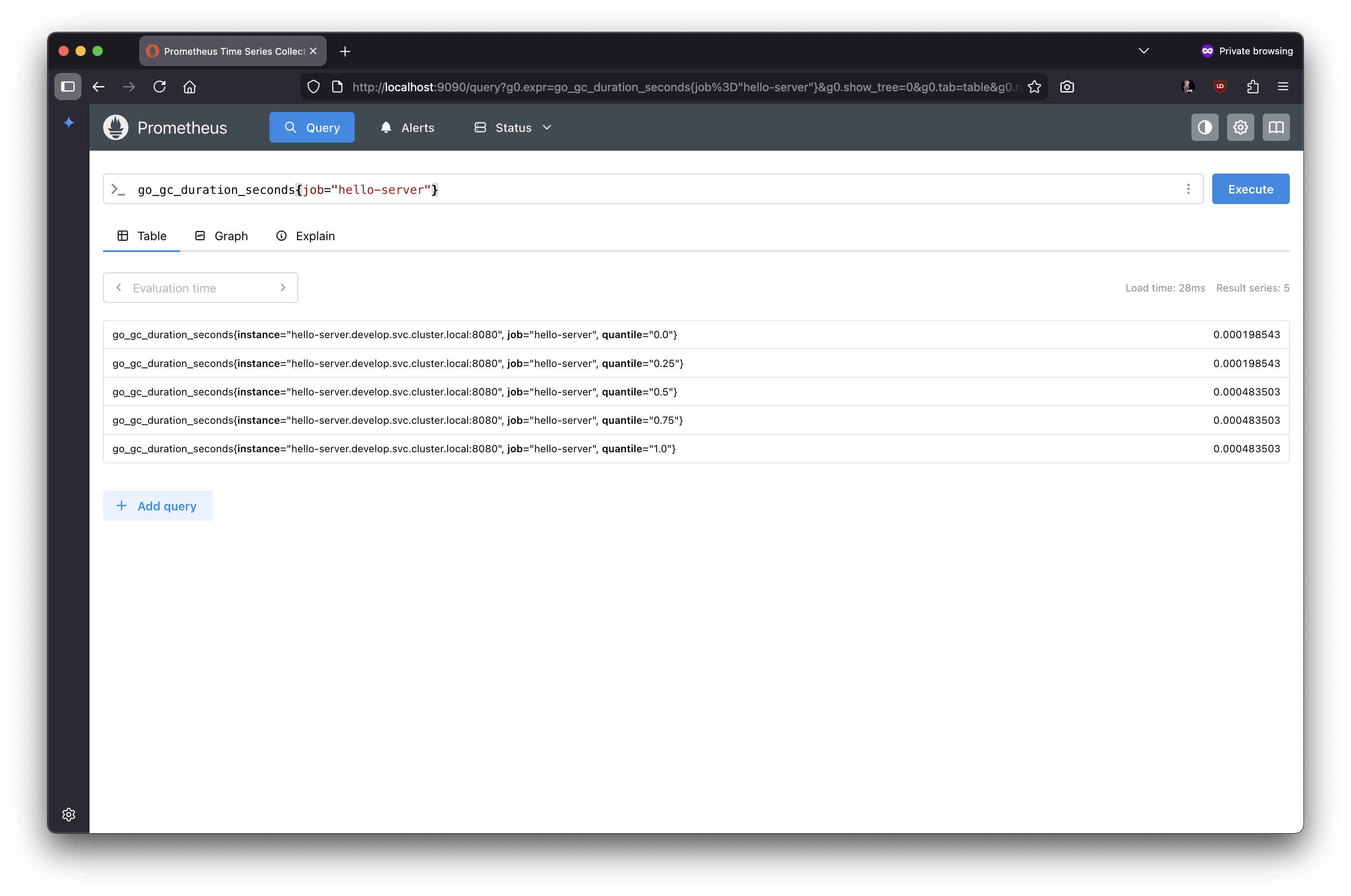
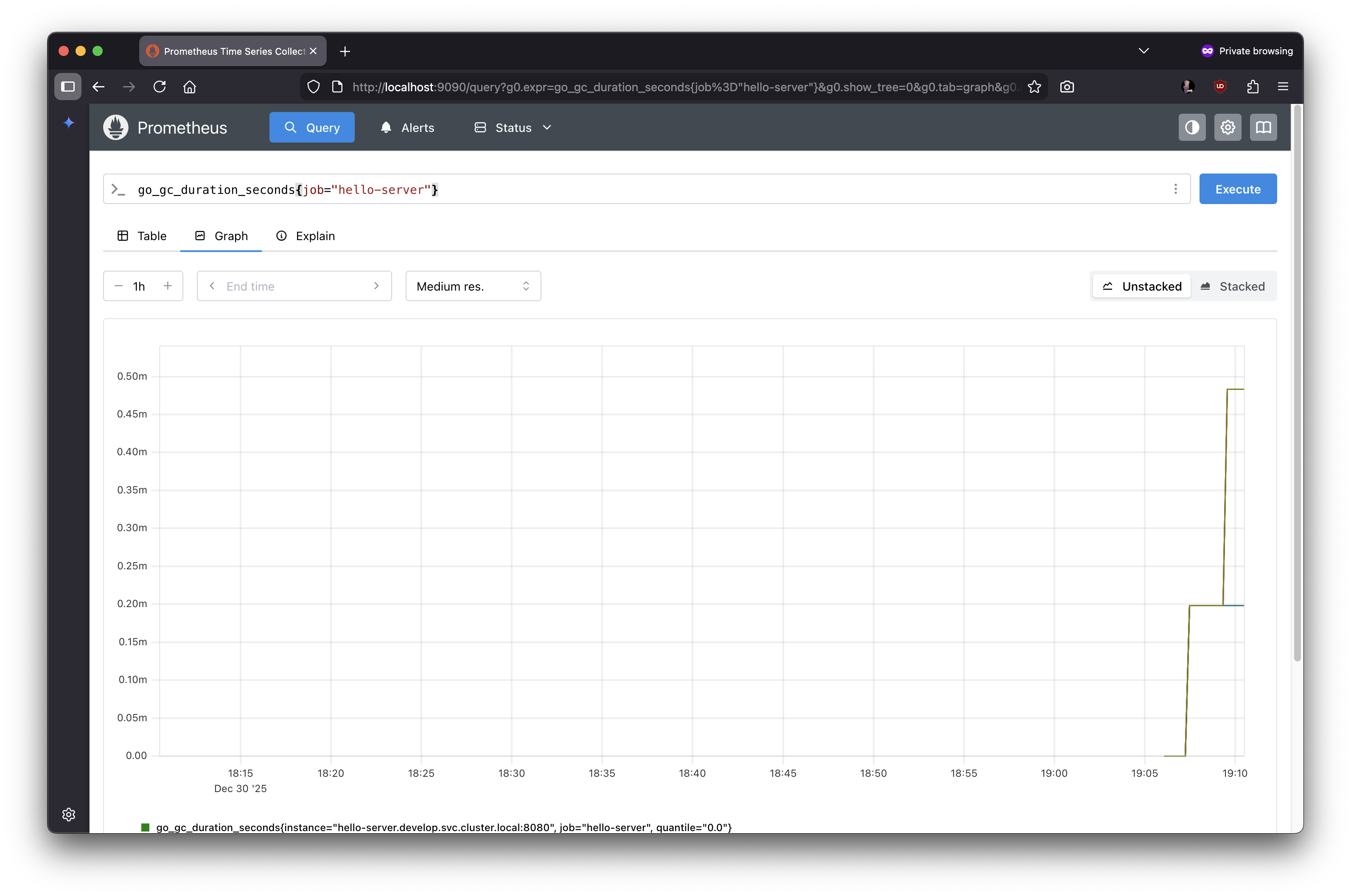
11.3.5 Grafana에 접속하기
port-forward를 설정하고 접속해보자.
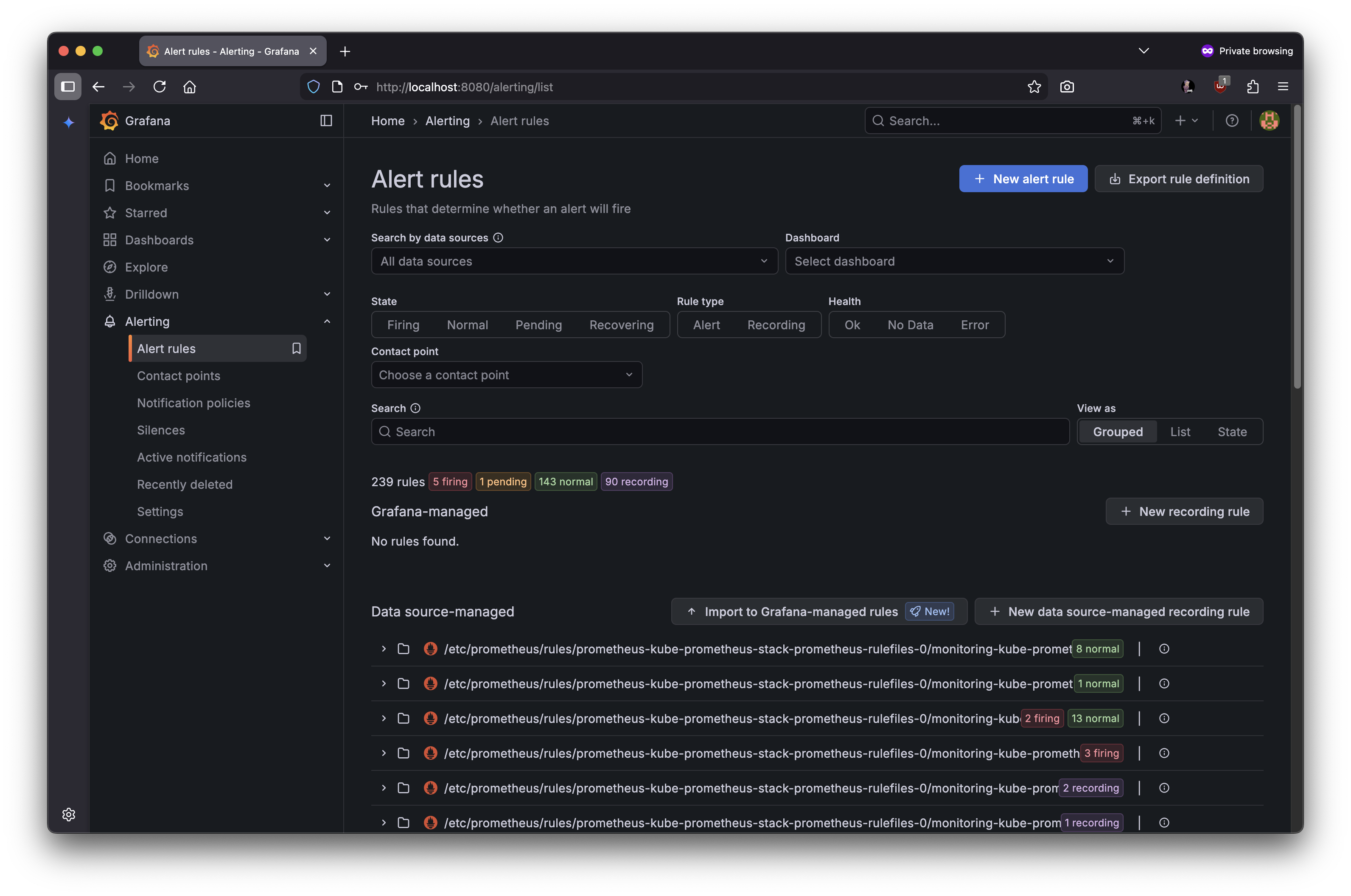
- Alerting rules